r quanteda|vcorpus package in r : solutions Fuentes disponibles de corpus. quanteda tiene un simple y poderoso paquete .
webWatch Nurse Jackie Season 1. Piloto. Episode 1 - 28 Mins. Sweet 'n' All. Episode 2 - 29 Mins. Chicken Soup. Episode 3 - 28 Mins. Enfermeira da escola. Episode 4 - 26 Mins. .
{plog:ftitle_list}
17 de set. de 2020 · From the creators of Ori and the Blind Forest comes the highly-anticipated sequel, Ori and the Will of the Wisps. Embark on an all-new adventure in a .
wordfish quanteda
quanteda is an R package for managing and analyzing text, created and maintained by Kenneth Benoit and Kohei Watanabe. Its creation was funded by the European Research Council grant .readtext: An easy way to read text data into R, from almost any input format. spacyr: .External pointers allow quanteda’s tokens operations to pass references to the .
quanteda has the functionality to select, remove or compound multi-word .
2.4 Beginning the analysis. The code below uses the tokenized text to the .
Fuentes disponibles de corpus. quanteda tiene un simple y poderoso paquete .目前可用的语料库资源. quanteda有一个简单而强大的配套软件包用于加载文本文 .インストールが推奨されるパッケージ. quantedaには連携して機能を拡張する .
पैकेज इंस्टॉल करने के निर्देश. क्यूँकि quanteda CRAN पर उपलब्ध है, आप .
Overview and benchmarking approach. quanteda version 4.0 can process .quanteda: Quantitative Analysis of Textual Data. A fast, flexible, and comprehensive framework for quantitative text analysis in R. Provides functionality for corpus management, creating and .
A fast, flexible, and comprehensive framework for quantitative text analysis in R. Provides functionality for corpus management, creating and manipulating tokens and n-grams, exploring .The chapters cover a brief introduction to the statistical programming language R, how to import text data, basic operations of quanteda, how to construct a corpus, tokens objects, a .Welcome to the Quanteda Initiative. Based in London, the Quanteda Initiative is a UK non-profit organization devoted to the promotion of open-source text analysis software. Learn more. .readtext: An easy way to read text data into R, from almost any input format. spacyr: NLP using the spaCy library, including part-of-speech tagging, entity recognition, and dependency parsing. quanteda.corpora: Additional textual .
quanteda is an R package for managing and analyzing text, created and maintained by Kenneth Benoit and Kohei Watanabe. Its creation was funded by the European Research Council grant ERC-2011-StG 283794 .A fast, flexible, and comprehensive framework for quantitative text analysis in R. Provides functionality for corpus management, creating and manipulating tokens and n-grams, exploring .
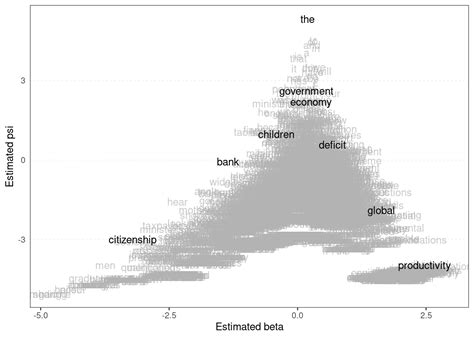
wordfish
We also outline approaches for changing the unit of analysis (reshaping and segmenting corpora), how to filter a text corpus based on variables associated with texts, how to retrieve the raw .A fast, flexible, and comprehensive framework for quantitative text analysis in R. Provides functionality for corpus management, creating and manipulating tokens and n-grams, exploring .The quanteda package has become the starting point for all my text analysis projects in R. This is due to its superb ability to prepare the data for analysis regardless of the method one might prefer. When the data is prepared, . What is quanteda? In order to analyze text data, R has several packages available. In this blog post we focus on quanteda.quanteda is one of the most popular R packages for the quantitative analysis of textual data that .
非常需要有一个合适的格式来保存并进行操作,quanteda填补了这个空白。虽然tidytext非常好,但是它主要还是利用了tidyverse的生态系统,而quanteda则很早就面向了文本挖掘的常见问题,并提出了在R中高效的解决 .
9.4.2 The Structure of a quanteda Corpus Object. As we will see with most of the core object classes in quanteda, its text analytic objects tend to be special versions of common R object types. In the R language, the atomic data type for recording textual .We would like to show you a description here but the site won’t allow us.We would like to show you a description here but the site won’t allow us.Details. quanteda makes it easy to manage texts in the form of a corpus, defined as a collection of texts that includes document-level variables specific to each text, as well as meta-data. quanteda includes tools to make it easy and fast to manipulate the texts in a corpus, by performing the most common natural language processing tasks simply and quickly, such as .
Introduction to quantitative text analysis using quanteda. 1. Introduction Install packages R commands 2. Data Import Pre-formatted files Multiple text files Different encodings 3. Basic Operations Workflow Corpus .Introduction to quantitative text analysis using quanteda. 1. Introduction Install packages R commands 2. Data Import Pre-formatted files Multiple text files Different encodings 3. Basic Operations Workflow Corpus .
Introduction to quantitative text analysis using quanteda. 1. Introduction Install packages R commands 2. Data Import Pre-formatted files Multiple text files Different encodings 3. Basic Operations Workflow Corpus .quanteda does not implement topic models, but you can fit LDA and seeded-LDA with the seededlda package. LDA. k = 10 specifies the number of topics to be discovered. This is an important parameter and you should try a variety of values and validate the outputs of your topic models thoroughly.License type: GPL-3. For license details, visit the Open Source Initiative website.; Compilation requirements: Some R packages include internal code that must be compiled for them to function correctly. The quanteda package has compilation requirements. Required dependencies: A required dependency refers to another package that is essential for the functioning of the main .

Toggle navigation quanteda 4.0.2. Quick Start Quick Start Guide; Guía de Inicio Rápido; . Source: R/dfm_weight.R. dfm_tfidf.Rd. Weight a dfm by term frequency-inverse document frequency (tf-idf), with full control over options. Uses fully sparse methods for efficiency.
With quanteda_options() you can get or set global options affecting functions across quanteda.One very useful feature is changing the number of threads to use in parallelised functions. By default, quanteda uses two threads, but depending on the RAM of your machine, you can use more than two threads. For instance, quanteda_options("threads" = 10) will use .
tokens_ngrams() is an efficient function, but it returns a large object if multiple values are given to n or skip.Since n-grams inflates the size of objects without adding much information, we recommend generating n-grams more selectively using tokens_compound().tokens_compound().Details. The function fcm() provides a very general implementation of a "context-feature" matrix, consisting of a count of feature co-occurrence within a defined context. This context, following Momtazi et. al. (2010), can be defined as the document, sentences within documents, syntactic relationships between features (nouns within a sentence, for instance), or according to a window.We would like to show you a description here but the site won’t allow us.Introduction to quantitative text analysis using quanteda. 1. Introduction Install packages R commands 2. Data Import Pre-formatted files Multiple text files Different encodings 3. Basic Operations Workflow Corpus .
Package ‘quanteda’ September 4, 2024 Version 4.1.0 Title Quantitative Analysis of Textual Data Description A fast, flexible, and comprehensive framework forx: a character or corpus object containing the texts. measure: character vector defining the readability measure to calculate. Matches are case-insensitive. See other valid measures under Details.Source: R/kwic.R. kwic.Rd. For a text or a collection of texts (in a quanteda corpus object), return a list of a keyword supplied by the user in its immediate context, identifying the source text and the word index number within the source text. (Not the line number, since the text may or may not be segmented using end-of-line delimiters.) . Please have a look at the snippet at the end of this post. I run a simplified tutorial example of topic modeling with quanteda, but once the model has finished running, I find it difficult to extract the word with the highest probabilities in each topic and visualize them as Julia Silge does in the example mentioned in the reprex.
This is the draft version of Text Analysis Using R. This book offers a comprehensive practical guide to text analysis and natural language processing using the R language. We have pitched the book at those already familiar with some R, but we also provide a gentle enough introduction that it is suitable for newcomers to R.quanteda. Quantitative Analysis of Textual Data. A fast, flexible, and comprehensive framework for quantitative text analysis in R. Provides functionality for corpus management, creating and manipulating tokens and ngrams, exploring keywords in context, forming and manipulating sparse matrices of documents by features and feature co-occurrences, analyzing keywords, .Research Council (ERC-2011-StG 283794-QUANTESS), quanteda is now supported by the Quanteda Initiative, a non-profit organization founded in 2018 to provide ongoing support for the “quanteda ecosystem” of open-source text analysis software. References Allaire, J., Francois, R., Ushey, K., Vandenbrouck, G., Geelnard, M., & Intel. (2018). quanteda is one of the most popular R packages for the quantitative analysis of textual data that is fully-featured and allows the user to easily perform natural language processing tasks.
27 de nov. de 2023 · Acompanhe o sorteio da Lotomania 2552 e confira o resultado do dia 27 de novembro de 2023, segunda-feira, com o prêmio de hoje estimado em R$ 3.500.000,00 (três milhões e quinhentos mil reais). . Avenida Paulista, 750, e o resultado da Lotomania 2552 divulgado a partir das 20:00 horas no painel de resultados do .
r quanteda|vcorpus package in r